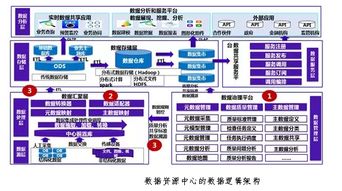
深度學(xué)習(xí)推薦系統(tǒng)的工程實現(xiàn)概要 數(shù)據(jù)處理與存儲服務(wù)
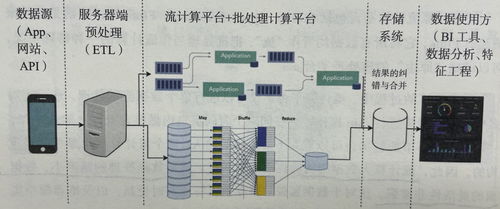
在深度學(xué)習(xí)推薦系統(tǒng)的工程實現(xiàn)中,數(shù)據(jù)處理和存儲服務(wù)構(gòu)成了系統(tǒng)的核心基礎(chǔ)。這些服務(wù)不僅決定了推薦模型的輸入質(zhì)量,還直接影響系統(tǒng)的可擴(kuò)展性、實時性和穩(wěn)定性。
數(shù)據(jù)處理的工程流程
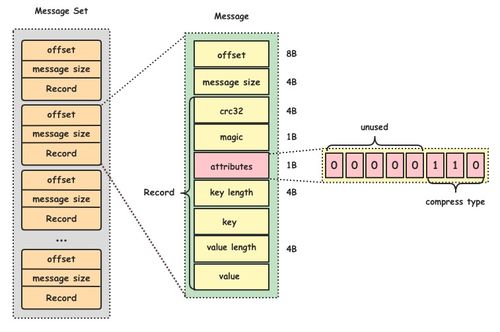
數(shù)據(jù)處理主要包括數(shù)據(jù)采集、清洗、特征工程和樣本生成等環(huán)節(jié)。系統(tǒng)通過日志收集用戶行為數(shù)據(jù)(如點擊、瀏覽、購買記錄)、物品屬性數(shù)據(jù)以及上下文信息。這些原始數(shù)據(jù)往往存在噪聲和缺失值,需經(jīng)過清洗和歸一化處理。隨后,特征工程階段將原始數(shù)據(jù)轉(zhuǎn)化為模型可用的特征,包括數(shù)值型特征(如用戶年齡、物品價格)、類別型特征(如用戶性別、物品類別)以及序列特征(如用戶歷史行為序列)。對于深度學(xué)習(xí)模型,常采用嵌入技術(shù)將高維稀疏特征映射為低維稠密向量。樣本生成模塊根據(jù)正負(fù)樣本比例構(gòu)建訓(xùn)練集,并可能引入負(fù)采樣策略以應(yīng)對數(shù)據(jù)不平衡問題。
存儲服務(wù)的架構(gòu)設(shè)計
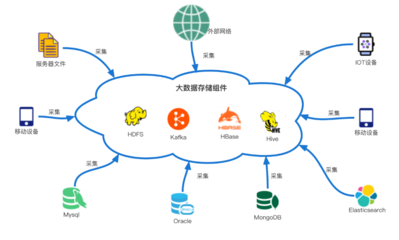
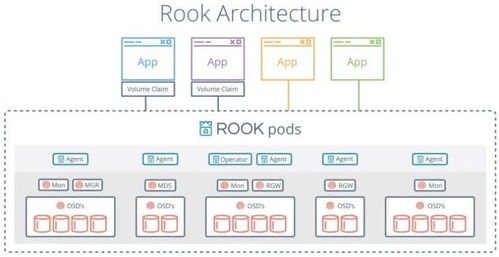
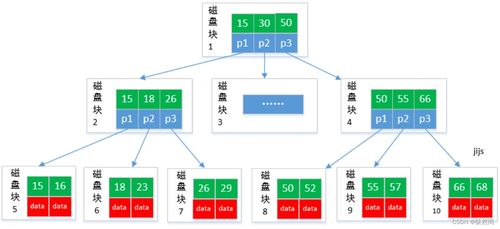
存儲服務(wù)需支持海量數(shù)據(jù)的高效存取,通常采用分層存儲架構(gòu)。實時數(shù)據(jù)(如用戶實時行為)存入低延遲的NoSQL數(shù)據(jù)庫(如Redis或HBase),以支持在線推薦服務(wù)的即時響應(yīng)。批處理數(shù)據(jù)(如歷史行為日志)則存儲在分布式文件系統(tǒng)(如HDFS)或數(shù)據(jù)倉庫(如Hive)中,用于離線模型訓(xùn)練。特征存儲系統(tǒng)(如Feast或Tecton)專門管理特征數(shù)據(jù),確保特征的一致性復(fù)用和快速檢索。元數(shù)據(jù)存儲(如MySQL)用于記錄數(shù)據(jù)版本、模型版本和實驗配置,保障系統(tǒng)的可追溯性。
關(guān)鍵挑戰(zhàn)與優(yōu)化策略
工程實踐中,數(shù)據(jù)處理和存儲面臨數(shù)據(jù)一致性、實時性與成本控制的挑戰(zhàn)。為保障數(shù)據(jù)一致性,需實施嚴(yán)格的數(shù)據(jù)血緣追蹤和Schema管理。實時性方面,通過流處理框架(如Flink或Kafka Streams)實現(xiàn)實時特征計算,減少數(shù)據(jù)延遲。成本控制則依賴數(shù)據(jù)生命周期管理,例如對冷熱數(shù)據(jù)實施分層存儲,并采用數(shù)據(jù)壓縮技術(shù)減少存儲開銷。
高效的數(shù)據(jù)處理和存儲服務(wù)是深度學(xué)習(xí)推薦系統(tǒng)成功落地的基石。通過模塊化設(shè)計、自動化流水線及智能監(jiān)控,工程團(tuán)隊能夠構(gòu)建出高可靠、低延遲的數(shù)據(jù)基礎(chǔ)設(shè)施,從而驅(qū)動推薦模型持續(xù)優(yōu)化與業(yè)務(wù)增長。
如若轉(zhuǎn)載,請注明出處:http://www.ktzxxx.cn/product/19.html
更新時間:2026-05-24 03:56:26